Two weeks ago, I attended PyCon.DE. It was an amazing experience; the talks and the people I met there have become an additional source of motivation and inspiration for me. From the people who worked as data scientists, I heard a lot about containerization or working with open source projects like Dask or Arrow. Training models in Jupyter Notebook is only a tiny part in a data scientist’s daily work - handling infrastructure requirements is often more important. Below is a list of talks about topics I would like to try out in the future or read about in more detail:
The first talk introduced NLP library spaCy, which I chose to try out in my next project. Coincidentally, the Yelp company booth was advertising their Yelp Dataset Challenge, and one of their available datasets contained user reviews. And so, my first NLP project was born: Sentiment analysis based on Yelp review data.
The dataset
The Yelp reviews dataset is a 4GB file with line-delimited JSON objects. With head <path to json file> we can see the first couple of lines to get a feeling for the format.
{
"review_id": "LWUtqzNthMM3vpWZIFBlPw",
"user_id":"msQe1u7Z_XuqjGoqhB0J5g",
"business_id":"atVh8viqTj-sqDJ35tAYVg",
"stars":2,
"date":"2012-11-09",
"text":"Food is pretty good, not gonna lie. BUT you have to make sacrifices if you choose to eat there. It literally takes an hour to an hour and a half to deliver food.Seriously. EVERY SINGLE TIME. Doesnt matter if we order at 8am, 10am or 1pm. Never fails, they take F-O-R-E-V-E-R. If you dont get what you ordered or you are upset by them delivering your breakfast around LUNCH time, be ready to have the owner talk down to you and be a total bitch to you for i dont know, justwanting what you pay for?! \n\nIts over priced. But its decently tasteful food. Takes forever. Owners awitch. And i'm pretty sure that they continuing forget to pack my extra ranch just to piss me off. \n\nEnd Rant. \n\nPS- I've never gone in there to eat because i frankly, i'd rather tip the nice delivery driver then the ignorant imbeciles that work in the dining area. \n\nPPS- My hot chocolate today was cold.They should call it Cold Chocolate. Or start caring if their hot chocolate is hot. One of the two wouldbe great!",
"useful":1,
"funny":2,
"cool":1
}
The dataset has a size too big to be comfortably loaded into memory at once with pandas. I therefore looked into Dask, a pandas-compatible library which can handle big data. With dask, I can load and (parallelly) process partitions of big dataframes.
After experimenting around for a while, the first preprocessing stage was defined with the following steps
- replace non-English reviews with a placeholder text “NON_ENGLISH_REVIEW”
- remove URLs and email addresses from review texts
- remove
\n, =, ", -, ), ( from review texts
- adjust expressions like “Awesome!!!My” (becomes “Awesome. My”) so that spaCy won’t identify the entire expression as one token later on
- map number of stars to a sentiment class in \(\{-1,0,1\}\)
- discard everything but the processed text and the sentiment class
- store processed dataset in parquet files
The above steps are applied before using spaCy. With spaCy, I can drop punctuations and non-alphabetic tokens. Since spaCy’s stop word list contains words which I consider important for sentiment analysis (e.g. “not”, “very”), a custom stop word list is used. After processing, I throw away all reviews with less than 5 tokens, leaving a 1.5GB dataset with
- 5,959,966 English reviews, among which
- 3,951,361 are positive with an average length of 61.67 tokens
- 667,544 are neutral with an average length of 89.49 tokens
- 1,341,061 are negative with an average length of 84.07 tokens
The above numbers show that the dataset is imbalanced - there are almost six times as many samples for the positive class as for the neutral class. This will be important when the model for sentiment classification is trained.
Below is a distribution plot for the number of tokens in each sentiment class.
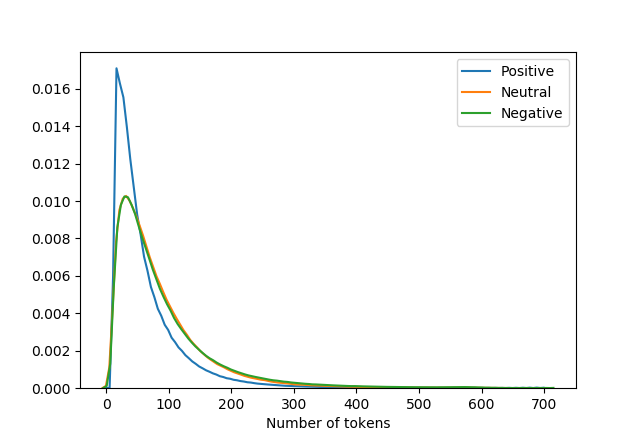
With spaCy, I can also look at the words identified as out-of-vocabulary. These words are mostly typos or exotic food names (“Schweinsbraten”, “etouffee”, “sopapillas”). I marked these words and filtered them out. There is one exception to the rule: spaCy is currently unable to recognize the word “number”, so I keep the word as it is.
SpaCy’s part-of-speech tagger is very useful when it comes to categorizing words as adjectives, nouns or verbs. I use this information to analyze which adjectives are predominantly used for different sentiment classes. The word cloud at the top of the picture shows the 50 most used adjectives in positive reviews, the word cloud in the middle shows the top 50 words for neutral reviews and the word cloud at the bottom shows the top 50 words for negative reviews. It is easy to see that the sentiment class differ, and words like “nice”, “good” or “great” appear in all classes with a different distribution.
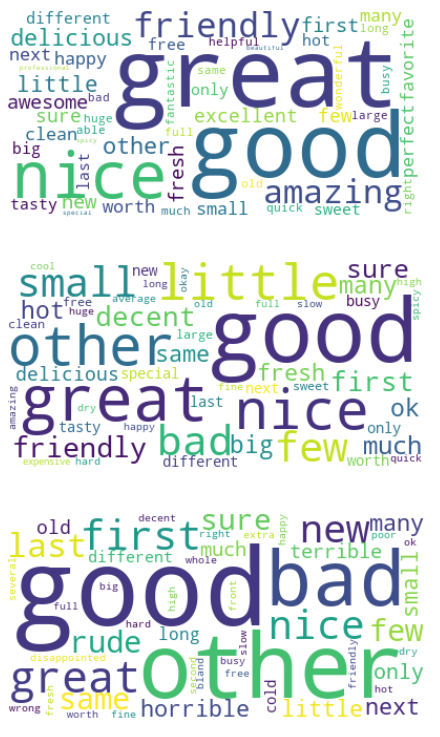
When words (unigrams) like “great” appear in a negative review, it is often in conjunction with a negation (“not great”). This is a motivation to consider unigrams as well as bigrams and trigrams for vocabulary determination. I use gensim’s Phrases model and Dictionary as preparation for later text vectorization methods like TF-IDF. I limit the vocabulary size out of performance concerns with filter_extremes.
from gensim.models.phrases import Phrases, Phraser
from gensim.corpora import Dictionary
from collections import Counter
def extract_phrases(df):
"""
Train bigram and trigram phrasers
Input:
- df: dataframe with column "text"
"""
def wrapper(generator):
for item in generator:
yield item.text.split(" ")
vocab = Counter()
vocab_final = Counter()
bigram_phrases = Phrases(wrapper(df.itertuples()), min_count=5, threshold=1)
bigram = Phraser(bigram_phrases)
trigram_phrases = Phrases(bigram[wrapper(df.itertuples())], min_count=5, threshold=1)
trigram = Phraser(trigram_phrases)
bigram.save("./vocab/bigram")
trigram.save("./vocab/trigram")
def create_dct(df,bigram,trigram,save):
"""
Create dictionary from dataframe
Input:
- df: dataframe with column "text"
- bigram: bigram phraser
- trigram: trigram phraser
- save: if true, vocabulary is saved in files
"""
def wrapper_phrase(generator):
for item in generator:
ngram = trigram[bigram[item.text.split(" ")]]
yield ngram
dct = Dictionary.from_documents(wrapper_phrase(df.itertuples()))
dct.filter_extremes(no_below=1000, no_above=0.80, keep_n=150000)
if save == True:
dct.save_as_text("./vocab/gensim_dct.txt")
dct.save("./vocab/gensim_dct")
The final vocabulary has around 15600 ngrams. Some example ngrams are great_atmosphere, too_expensive, definitely_come_back. Surprisingly, gensim’s Phraser did not identify the ngrams “not_great” and “not_good”. Instead, there are other combinations involving negations: not_bad_either, not_big_fan, not_bother, etc.
In the next blog post, I will describe how I did the actual sentiment analysis. The relevant code will be uploaded to this repo.